Transformer architecture
The fundamental element of the large language models that turned out to be a game changer in the field of generative AI is the so-called transformer architecture. It was introduced in the paper "Attention Is All You Need" published in December 2017.
Attention Is All You Need paper
The simplified version of the transformer architecture looks like this:
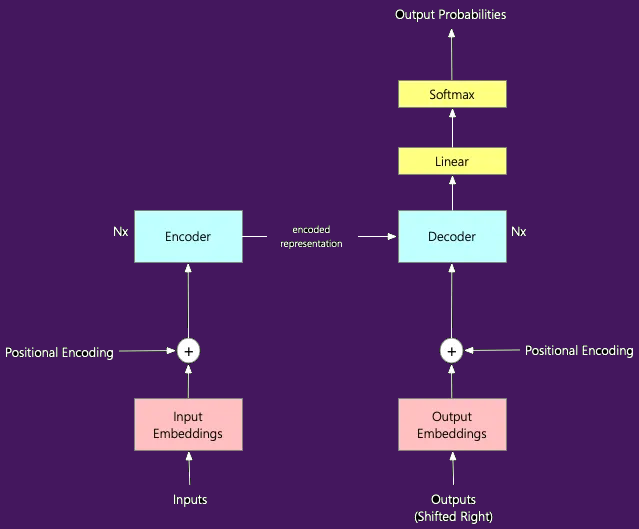
Let’s take a look at the components that make up this architecture:
-
Inputs - an input can be for example a sentence that should be translated into a different language.
Since the machine learning models understand only numbers but not texts, the inputs should be encoded (= converted into a numerical format).
-
Embeddings - embeddings are learned vector representations of the input tokens (words or subwords) that capture semantic and syntactic information.
They function as a kind of a dictionary and help the machine learning model to understand the meaning of the words.
-
Positional encoding - positional encodings are added to the input embeddings to make sure that the original words’ order is preserved.
This is important because unlike former language models, the language models based on transformers, process the input embeddings not one by one, but analyze all of them at once. The main advantage of processing the entire input sequence at once (parallelization) is that it allows for capturing long-range dependencies more effectively, which was a limitation of previous sequential models like RNNs. On the other hand, though, problems with information related to words’ order may occur.
-
Encoder - the encoder processes the input.
The role of the encoder is to capture the complex contextual relationships between words and their meaning. It does it through the attention mechanism by applying the so-called attention layers (Nx).
-
Decoder - the main task of the decoder is to generate the output in a form that is understandable for humans, for example a sentence translated into another language.
Similar to the encoder, the decoder also consists of attention layers (Nx). The decoder takes the encoded representation from the encoder as input, and it also takes its own previously generated output (shifted right) as input, which is combined with the encoded representation through the attention mechanism. Multi-head attention mechanism is a key component of the transformer architecture and allows the model to attend to different representations of the input simultaneously.
Just like in case of the encoder, where inputs need to be converted into a numerical format, also the outputs (shifted right) have to go through the same process so that the model is able to understand them. They are then called output embeddings. They also undergo positional encoding, which helps the model understand the order of words in a sentence.
-
Linear - after the decoder produces the output, the linear layer performs some mathematical operations on this data using parameters such as weights and biases. It is a bit like assigning a score to each of the elements in the output.
-
Softmax - the softmax is applied to convert these scores into probabilities. In other words, it indicates how probable it is for each word to be present in the final output.
These layers are part of the final output layer, which generates a probability distribution over the vocabulary for the next token prediction.
Both the encoder and decoder consist of multiple identical layers, each containing a multi-head attention sublayer and a feed-forward sublayer, with residual connections and layer normalization. -
Output probabilities - the final output, for example a sentence translated into another language.